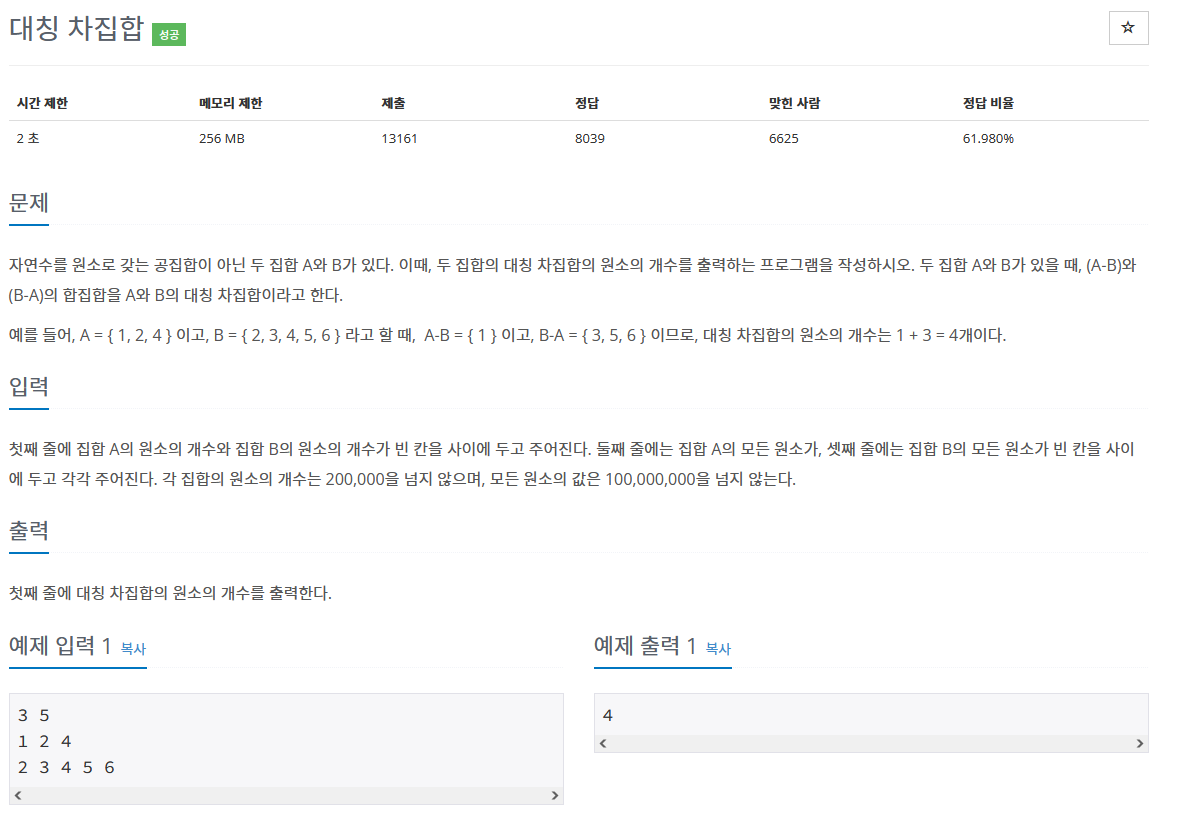
개념적으로 크게 어렵지 않다.
이걸 풀기 위해 검색하면서, 집합자료형인 set에 대해서 알게되었다.
set 자료형은 array와 다르게, 순서가 없다는 점. 아직은 갓 알게된 터라, key값이 필요없는 map 자료형 느낌으로 쓰고있다.
try 1. 이클립스에서는 성공했으나, 시간초과로 실패.
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.StringTokenizer;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st1 = new StringTokenizer(br.readLine()," ");
StringTokenizer st2 = new StringTokenizer(br.readLine()," ");
StringTokenizer st3 = new StringTokenizer(br.readLine()," ");
int a = Integer.parseInt(st1.nextToken());
int b = Integer.parseInt(st1.nextToken());
ArrayList<Integer> setA = new ArrayList<>(a);
ArrayList<Integer> setB = new ArrayList<>(b);
for (int i=0; st2.countTokens()!=0; i++) {
setA.add(Integer.parseInt(st2.nextToken()));
}
for (int i=0; st3.countTokens()!=0; i++) {
setB.add(Integer.parseInt(st3.nextToken()));
}
HashSet<Integer> hsA = new HashSet<>(setA);
HashSet<Integer> hsB = new HashSet<>(setB);
HashSet<Integer> hsAb = new HashSet<>(setA);
HashSet<Integer> hsBa = new HashSet<>(setB);
hsAb.removeAll(setB);
hsBa.removeAll(setA);
System.out.println(hsAb.size() + hsBa.size());
}
}
try2. 다른 풀이방법을 찾다가 클론코딩으로 성공.
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.HashSet;
import java.util.Set;
import java.util.StringTokenizer;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine()," ");
int a = Integer.parseInt(st.nextToken());
int b = Integer.parseInt(st.nextToken());
st = new StringTokenizer(br.readLine()," ");
Set<Integer> setA = new HashSet<>(a);
Set<Integer> setB = new HashSet<>(b);
for (int i=0; i<a; i++) {
setA.add(Integer.parseInt(st.nextToken()));
}
st = new StringTokenizer(br.readLine()," ");
for (int i=0; i<b; i++) {
setB.add(Integer.parseInt(st.nextToken()));
}
int count = 0;
for (int num : setA) {
if (!setB.contains(num)) {
count++;
}
}
for (int num : setB) {
if (!setA.contains(num)) {
count++;
}
}
System.out.println(count);
}
}
코드 리뷰
try1의 문제점을 짚어보자면,
1.
StringTokenizer를 쓸데없이 많이 선언함. 어차피 거쳐가는 자료형인데 굳이?
하지만 StringTokenizer를 1개쓸걸 3개썼다고 딱히 시간초과의 요인인것 같지는 않다.
2. Set 선언이 너무 많음.
try2에서 2개만 선언한데 비해, 너무 많은 Set 선언을 남발했음.
나름 Set 자료형이 자료 수의 2배만큼의 size를 확보한다하길래, 타이트하게 크기까지 지정해주긴 했는데...
3. Set을 통한 매소드 콜이 너무 많음.
사실상 이게 시간초과의 주범일듯.
A와 B의 각자의 차집합을 구하는 매소드를 호출했는데, 이 부분에 있어서
try2에 시도했던 반복문보다 더 복잡했을 가능성이 크다.
try2의 반복문은 기존 Set 변수들을 건들 필요가 없었다. 외부에서 포함유무만 따지고 셈만 해주면 끝.
하지만, 차집합을 구하는 매소드는 집합 구성 자체도 변화해야했다. 목적에 비해 너무 많은 연산이 들어감.
그리고 대칭차집합 = 합집합 - 교집합으로 구할 수도 있었다. 다만 최적화에 관여하는건 아니라서, 그냥 논리 참고용.
'백준 문제풀이' 카테고리의 다른 글
| 1085. 직사각형에서 탈출 (0) | 2022.10.10 |
|---|---|
| 11478. 서로 다른 부분 문자열의 개수 (자바, Java) (0) | 2022.10.10 |
| 1764. 듣보잡 (자바, Java) (1) | 2022.10.03 |
| 10816. 숫자 카드 2 (자바, Java) (1) | 2022.10.03 |
| 1620. 나는야 포켓몬 마스터 이다솜 (0) | 2022.10.03 |